在使用大语言模型时,你会遇到如下四个问题: 偏见,幻觉,滞后,过时
由于训练用到的语料库无法完全人工甄选,所以会混入一些错误的观点的,就可能出现一些很垂直的领域或者问题答案带有偏见,例如政治,种族,主观的观点,甚至生成代码等等。它毕竟不会思考,内部数据有什么就依照什么回答罢了。
大语言模型主要的能力的是预测接下来的文文字,所以创作类的答案基本都是可以的。但是由于语料源的不确定性,他自己无法判断答案的权威,因为它是不具备计算等人类大脑才有的能力的,那么他偏向推理,他会基于已有的数据做推理,就如推理这个词表达的,他会出错,会一本正经的胡说,给你错误的代码等等。如果给一个不了解问题和答案的人可能是个灾难,所以最终还是需要在这个领域足够资深的人用人脑去确定答案是否可用。
大模型训练存在数据滞后的,所以大家可以发现很多模型的名字会出现一些时间的后缀。那么在搜索更新的信息他是没有的
基于数据源的原因,再加上模型训练的时效性问题,还会出现过时的问题,也就是当时训练时的一些答案现在已经过时,例如某个人有100w个粉丝,可能过了半个月已经成了150w,但是模型可不知道,它还是按照100w粉丝来返回。
优化上述问题主要有两个方法:
- 模型微调(Fine-tuning)
- 检索增强生成(RAG)
第一种方法看起来对于特定领域是更好的方法,但是对于OpenAI这种规模的模型微调的成本极高,而且效率很低。那么主要就是第二个方法。
RAG的全称是检索增强生成 retrieval-augmented generation,这个概念来自于 Facebook AI 部门自然语言处理研究员们在 2020 年发表的一篇论文中。所以他的出现要远早于ChatGPT甚至LLM的出现,而不是因为ChatGPT后的实践方案。
简单地说,RAG是一种利用额外数据增强 LLM 知识的技术。你可能会想,哎,我把内容放在prompt里补充相关知识不就好了?这就要提到Token超限。使用过API你一定会遇到token数量限制的报错。假如你需要从一本小说里找到某个答案,而那个小说太长了,这就没办法直接补充了,而且还有一个不易发觉的问题,就是prompt越长会造成请求性能下降。
然后我们说回RAG,就是使用嵌入或其他搜索技术用与该主题相关的专业知识填充人工智能模型上下文。所以它主要的应用有如下2个方向:
- 大模型不擅长回答的垂直领域。例如openai是比较通用的模型,但是如果你问他一些非常细分领域的问题他回答不好,可以补充足够知识给用户使用,例如医学类的,建筑,法律等等。
- 回答封闭领域问题的产品或者应用。例如特定领域或组织的内部知识库。
其实在GPT-4里面OpenAI官方已经在朝着这个方向发展了,在使用ChatGPT时候它可以网络搜索获取实时信息,没有上下文的它先去搜索相关信息等等,但是我们在开发应用时需要自定义这个过程,因为开发者知道权威数据源,例如控制去哪里搜,怎么提取知识,另外既然数据源是自己的,还需要确定数据怎么存。
我们再回到Retrieval-Augmented Generation。通过名字也可以了解到,它结合了检索和生成的能力,为文本序列生成任务引入外部知识,相当于使模型在生成响应或文本时可以动态地从指定的知识库中检索相关信息。
工作原理
在正常情况下,LLM 会接受用户输入,根据它已经知道的信息创建响应。RAG 引入了一个信息检索组件,该组件首先从新数据源提取信息,再把用户查询和相关信息都提供给 LLM。LLM 使用新知识及其训练数据来创建更好的响应。它主要包含下面三部分:
索引(Indexing)
LLM原始训练数据集之外的就是外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可以以各种格式存在,例如文件、数据库记录等。
在LLM领域,一般使用嵌入(Embedding)将数据转换为数字表示形式并将其存储在向量数据库中,这个过程会创建一个生成式人工智能模型可以理解的知识库。这个过程也叫索引,就是将知识库转换为可搜索/查询的内容。
那什么是 Embedding?简单来说,Embedding 就是用一个数值向量“表示”一个对象的方法,对象可以是实物也可以是一个虚拟的东西,例如一本书,一部电影等等。
下面是一个用OpenAI嵌入的例子:
In [4]: e = client.embeddings.create(input='你好', model="text-embedding-ada-002")
In [5]: len(e.data[0].embedding)
Out[5]: 1536
In [6]: e.data[0].embedding[:3]
Out[6]: [0.0002545917232055217, -0.0060387649573385715, -0.002320892410352826]检索(Retrieval)
用户输入问题,会使用检索系统从大型文档集合中查找相关的文档或段落,这种查找其实是在向量数据库进行的语义搜索,也就是在向量空间中查找最相似的文本片段,如果形象点,可以把文本片段类比为在空间中的两个点,两个点越接近,它们就越相似。举个例子:
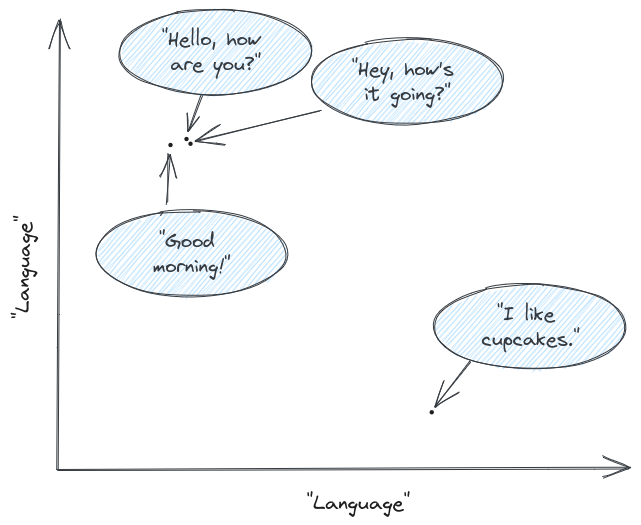
假设用户提问"Hello, how are you?",和 "Hey, how’s it going?" 几乎在同一个位置。另一个问候语"Good morning"也不太远。而"I like cupcakes"则完全与其他内容分开。那么最终,"Hey, how’s it going?"的相关性最高, "Good morning"稍微差一点,"I like cupcakes"相关性最差。当然实际上排序要比这个更复杂,如果你希望深入就得看相关论文了。
通过检索,就可以搜到外部数据源里的相关文本了。
增强 LLM 提示(Generation)
最后就是把原来的Prompt、检索到的相关文档组合成一个增强版本的提示,再请求模型并获取响应。这个其实技术含量不高,按需拼提示语即可。
视频
这个系列分为2个视频,下面的视频我将具体演示几个Rag例子:
延伸阅读
https://arxiv.org/abs/2005.11401 (opens in a new tab) https://www.infoq.cn/article/oyYuL6eNtxwRYxirbQ6o (opens in a new tab) https://platform.openai.com/docs/guides/embeddings/what-are-embeddings (opens in a new tab) https://github.com/huggingface/blog/blob/main/ray-rag.md (opens in a new tab) https://github.com/jxzhangjhu/Awesome-LLM-RAG (opens in a new tab)